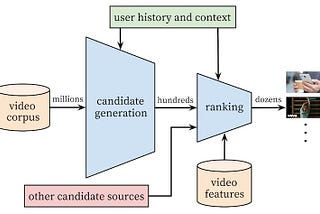
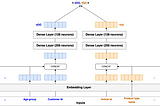
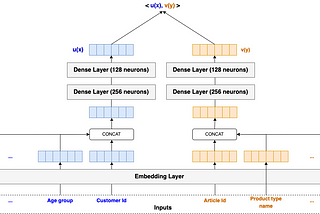
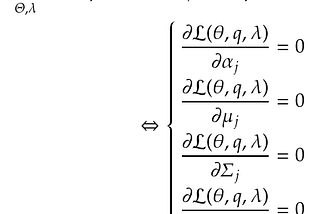PinnedBuilding a Multi-Stage Recommendation System (Part 1.1)Understanding candidate generation and the two-tower modelAug 13, 20229Aug 13, 20229
Published inTDS ArchiveMixture-of-Softmaxes for Deep Session-based Recommender SystemsModern session-based deep recommender systems can be somehow limited by the softmax bottleneck like their language model cousinsJul 18, 2023Jul 18, 2023
Published inTDS ArchiveA Complete Tutorial on Off-Policy Evaluation for Recommender SystemsHow to reduce the offline-online evaluation gapMar 11, 2023Mar 11, 2023
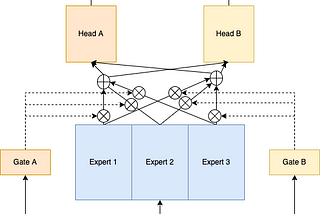
Building a multi-stage recommendation system (part 2.1)Heavy ranking model strategy and design — Multi-gate Mixture-of-ExpertsSep 27, 2022Sep 27, 2022
Building a multi-stage recommendation system (part 1.2)Implementation of the two-tower model and its application to H&M dataAug 25, 20224Aug 25, 20224
Published inTDS ArchiveHow CatBoost encodes categorical variables?One of the key ingredients of CatBoost explained from the ground upFeb 10, 20213Feb 10, 20213
Published inTDS ArchiveFrom Boosting to GradientBoostA friendly but rigorous explanationJan 26, 2021Jan 26, 2021
Published inTDS ArchiveMultinomial Mixture Model for Supermarket Shoppers Segmentation (A complete tutorial)Complete analysis and implementation of a multinomial mixture model for supermarket shopper segmentation and predictive profiles predictionOct 14, 2020Oct 14, 2020
EM of GMM appendix (M-Step full derivations)This article is an extension of “Gaussian Mixture Models and Expectation-Maximization (A full explanation)”. If you didn’t read it, this…Sep 21, 20202Sep 21, 20202
Published inTDS ArchiveGaussian Mixture Models and Expectation-Maximization (A full explanation)The full explanation of the Gaussian Mixture Model (a latent variable model) and the way we train them using Expectation-MaximizationSep 11, 20202Sep 11, 20202